What is Life? Part II: Biomolecules and the Genetic Code
{category_name}So research and life have kept me from writing for the past month or so and during that time I did some thinking about the direction of the blog. It occurs to me that I’ve been heavy on physics and quite light on chemistry and biology which probably reflects my own bias concerning what aspects of life are common knowledge, a point that was driven home to me recently when I realized that a physicist friend of mine had no idea what proteins were or did. Before discussing the emergence of biological information, a digression seems to be in order, so I thought I would spend a post explaining what kinds of molecules make up living bodies and the kinds of things those molecules do in general.
Everyone knows more than they think they do about biochemistry already because, after all, we are what we eat. So to begin with, almost all of the molecules inside any living thing can be classified as either carbohydrate, protein, lipid or nucleic acid. Here’s a helpful diagram:
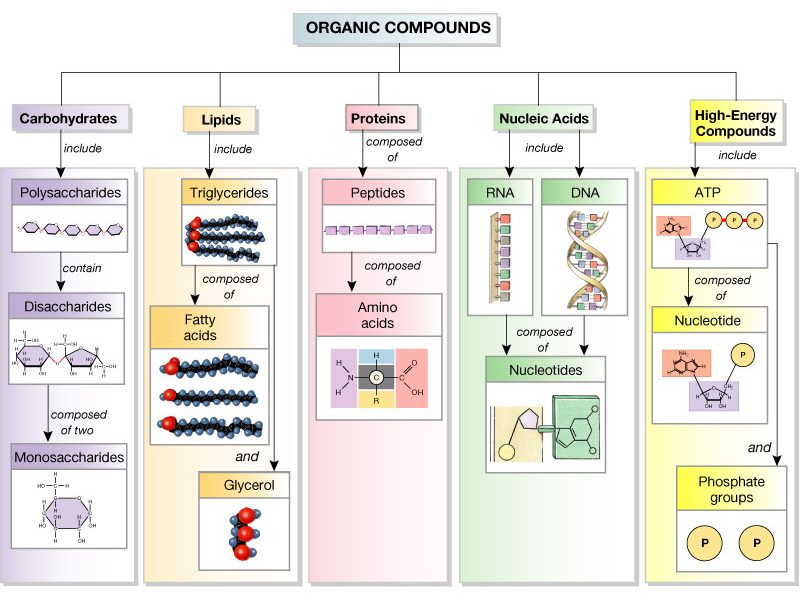
Lipids, which are fats and oils, make up the membranes of cells and intracellular compartments called organelles. Membranes are a crucial ingredient in cells because they create an oily phase that doesn’t mix with water thereby providing the basis for concentrating specific kinds of molecules in specific compartments. As we’ve discussed, concentrating a molecule is a way of forming a non-equilibrium material distribution which can perform organized work as that concentration gradient spontaneously dissipates toward its equilibrium value. So lipids are responsible for creating the boundary conditions necessary for cellular organization.
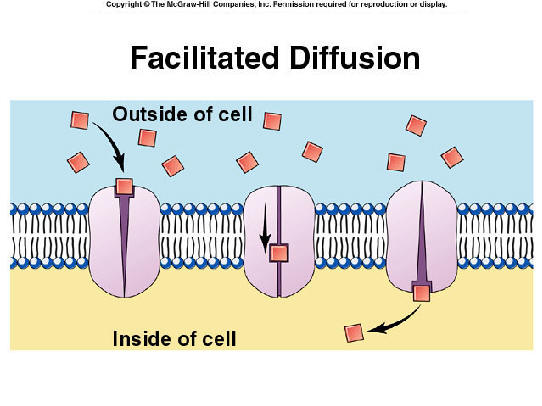
Here’s a cartoon of a protein in a membrane doing work to equilibrate a concentration gradient that exists because hydrophilic and/or charged particles can’t pass through the oily membrane:
Next up on our tour of biological macromolecules are carbohydrates. The carbs are the simplest polymers involved in life. Lipids are the only kind of the four macromolecule types which are not polymers. Carbohydrates, proteins, and nucleic acids are all polymers. This means that they are long chains formed by repeating chemical units (see the first picture). Carbohydrates consist of starches and sugars, and starches are simply long chains of the same kind of sugar molecule repeated over and over. The fact that starches contain the same sugar repeated over and over precludes them from containing information, in the same way that one cannot make a meaningful sentence by simply repeating the same word over and over. For this reason, starches are primarily used as simple fuel sources: they are degraded by proteins in order to store chemical potential in the cell. There are, however, instances where certain cells put specific kinds of sugars on their surface for purposes of sending or receiving a signal from another cell, and this constitutes a “sugar code” that is informational. But these processes are not essential to life and almost certainly emerged later in evolution.
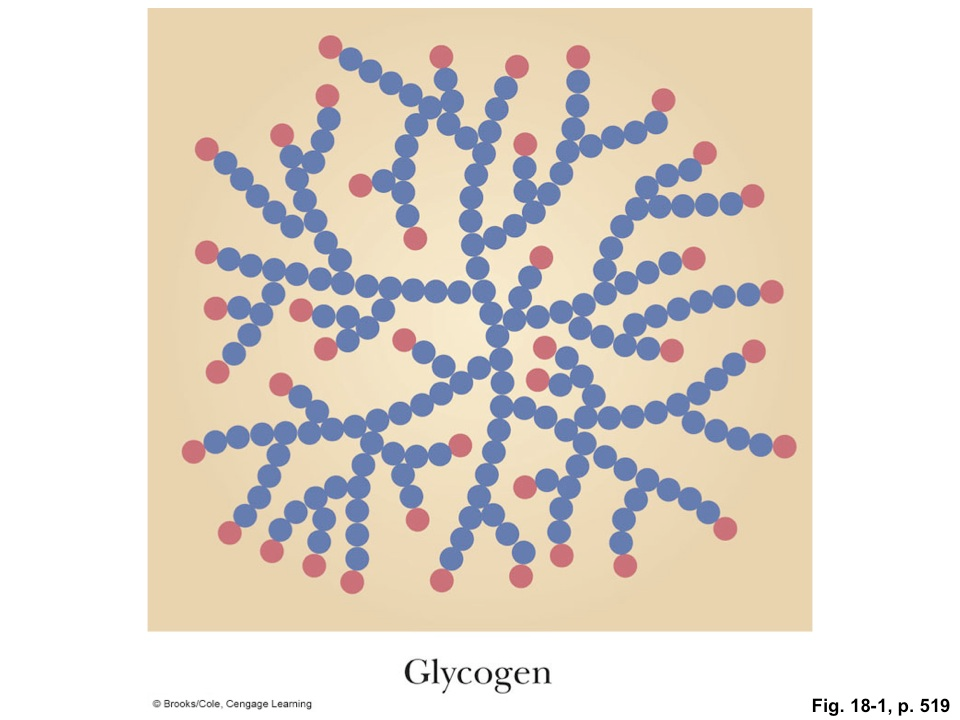
Here’s a cartoon of glycogen, which is the storage form of glucose (sugar) inside animal cells (like yours). The blue dots are glucose molecules and the red dots are the places where a protein can come along and chomp off a glucose to be burned (oxidized) by the cell for energy:
Ok so that doesn’t tell you a whole lot about lipids or carbs, but hopefully it should remind you that you are made up of a lot of fat and sugar and that even though you’re perhaps accustomed to thinking that you get too much of these things you also depend on them for survival and they constitute part of your being.
The last two macromolecule types constitute the central informational knot of life: proteins and DNA. Both are hetero-polymers: they are made up of different repeating units. DNA and RNA are both made up of four kinds of chemical units which we abbreviate A, T, C, and G (In RNA the T is a slightly different chemical abbreviated U and there are minor structural changes but the differences between DNA and RNA aren’t important for this discussion yet). Proteins are also heteropolymers made up of 20 different naturally occurring amino acids. Being a heteropolymer, unlike starch, means that proteins and nucleic acids are capable of carrying information. So here is the first, necessary but insufficient criteria for biochemical information: A given symbol set must be capable of being permuted in alternative arrangements.
Proteins and nucleic acids both meet this criteria because there are no physical or chemical constraints on them that determine, in advance, how the monomer units should be ordered when they form a polymer chain. DNA forms polymers in such a manner that it really makes no physical or chemical difference at all what the identity of the next nucleotide in the chain will be. Proteins contain a few more self-ordering rules due to the kinds of shapes that they make, so not all possible sequences of amino acids will polymerize into a protein as readily as will any possible sequence of nucleotides turn into a strand of DNA. Language is more like protein in this regard. For example, in English, when we find the letter ‘Q’ in a word it is highly probable that the next letter will be ‘U.’ Certain amino acids, likewise, would rather be next to one another or far away from one another in a sequence for energetic reasons. This seems like a footnote but it will be important when we contrast the metabolism-first view of emergence with the RNA-first view.
Ok so the central information pathway in a cell is known as the “central dogma” of molecular biology, and it says that the sequence of nucleotides in DNA are first “transcribed” into RNA and then “translated” into a protein. The process that “transcribes” the DNA into RNA is much more straightforward than the process that “translates” RNA into proteins. There is general consensus that life probably began with RNA as the exclusive information carrying molecule. DNA, however, is much more stable and lasts longer in water than does RNA and this probably constituted the rationale for selecting the DNA structure once it emerged through the randomizing directive to increase configurational entropy. The translation mechanism, however, is the genuine mystery which still confronts origin of life theory today.
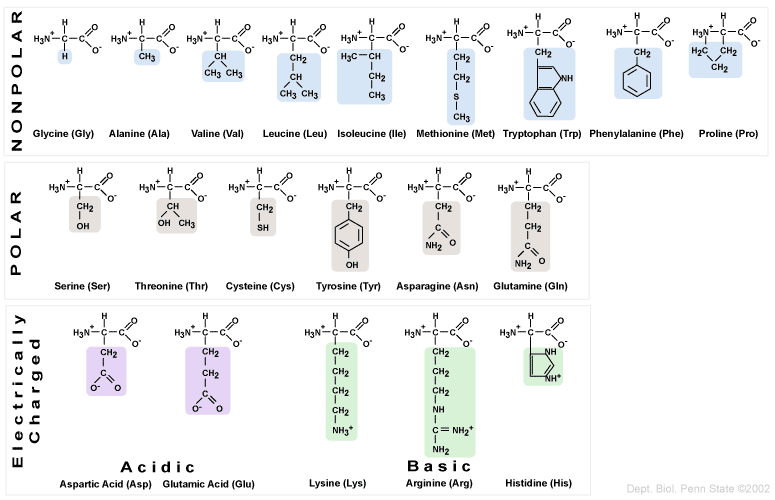
Here are the 20 natural amino acids, the monomer units of protein polymers:
And here are the four nucleotide bases of DNA:
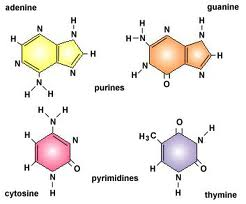
So when we talk about “translating” genes into proteins what we’re talking about is how the nucleotide sequence in a gene gets sent, in the form of RNA, to a large complex of protein and RNA molecules called a ribosome. The ribosome “reads” the nucleotide sequence on the RNA transcript and assembles a protein. That protein then goes off and does the chemistry that keeps you alive: moving food and signaling molecules through membranes, breaking down food and transducing signals inside cells, affecting the rates at which other proteins work, degrading and breaking down other old proteins, binding to and copying the DNA that codes for more proteins and on and on. Proteins do almost all of the chemistry that goes on inside cells. DNA contains the instructions to build proteins, but does not itself do any chemistry. Thus evolution has developed a division of labor between proteins which catalyze the chemistry of life and DNA which stores the information required to build this chemical capacity.
This is what constitutes “the genetic code.” The mathematics of translating a four-letter language into a 20-letter language necessitate that 3 nucleotides code for one amino acid. So every possible three letter combination of the four nucleotides is called a "codon." Here’s a table which connects the 64 possible (4 letters in three combinations means 4^3 = 64 possibilities) codons to the 20 amino acids they encode along with the message to start and stop protein synthesis:
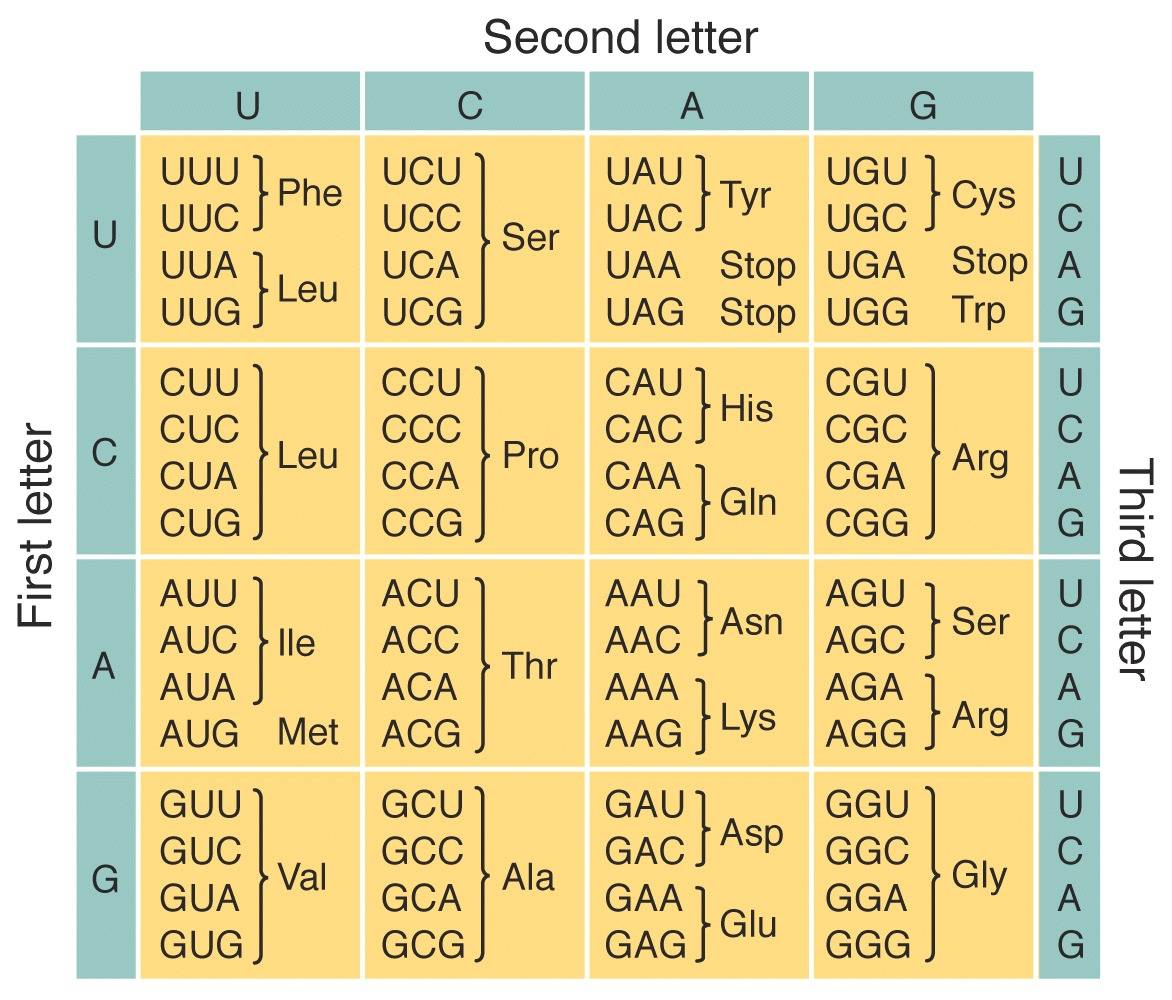
So the ribosome, which again, is itself nothing but an assemblage of proteins and RNA, performs this “translation” which makes proteins from RNA templates. The point that you should take away from this table can be inferred simply from the fact that it exists: The genetic code is the first instance in which biology exerts autonomy from chemistry. No chemical necessity or thermodynamic driving force explicitly connects the three nucleotides “CAU” to the amino acid histidine rather than the amino acid glutamine. Likewise no necessity connects the letters CAT to the existence of cute, furry pets. This is exactly why, if I know the language, the word cat conveys information to me. I was taught to associate that word with a phenomena, despite the fact that nothing about the sound itself tells me to associate this word with that phenomena. Likewise, the fact that the nucleotides themselves appear to have no chemical connection to the amino acids they code for is the very reason that we call it a code rather than just “genetic chemistry.”
But I emphasized the word appear when speaking about the connection between amino acids and their codons, because a code doesn’t simply spring into existence fully formed. So herein lies the central mystery: how does a non-equilibrium organization direct energy flow into the emergence of an informational code that is not itself predetermined by the laws of chemistry and physics? This theme may be compressed as the problem of the emergence of information. Thus far I have been describing the energetic constraints placed on pre-biotic evolution: how non-equilibrium distributions provide organizational contexts for the random motions of matter and energy. The problem to be addressed in future posts, for which I do not claim to have any clear solution, is to see how physics and chemistry could have conspired to turn these transient non-equilibrium states into information which could then be used to reproduce those same non-equilibrium conditions given the necessary resources.
Remember, a candle flame is an organized, non-equilibrium flow which exists to dissipate potential energy...but the candle does not have the complexity required to use that dissipating energy as a means for storing the information required to make another candle. Yet the chemistry which life uses to maintain itself is essentially the same as the chemistry powering the candle flame. How then, does chemistry become language? Next time we’ll take a close-up look at the ribosome and the translation process in order to set the stage for some possible solutions to this problem.
Thumbnail image is from here.